Bachelor/Master Thesis: Efficient Database for Synthetic Datasets for training and validating AI
Data plays a key role in a lot of modern technologies, particularly deep learning based systems. The more diverse and large the data-sets are, the better can one estimate the reliability these systems. Typically, these data-sets are collected through existing real world-information, either past databases are pruned and annotated to be suitable inputs for an algorithm, or exhaustive experiments are conducted to collect said data. In either case, a lot of manual effort and resources are required to collect, classify and label the data.
Simulations offer a solution to this tedious process and can generate the data synthetically. This data must not replace real-world data, but simply serve to make it richer. For computer-vision problems, one can use realistically modelled physical systems, e.g. robots, vehicles, traffic, and generate annotated and labelled sensor data (e.g. camera output or 3D point-clouds). It has been well established, that even not-so-realistic simulations can prove very advantageous in diversifying existing real data sets and in transfer learning approaches (learning from one domain and applying in another).

Docking in a satellite on the ISS requires high resolution optical scans
To harness the true power of physically realistic simulations, one needs thousands of simulations (100,000 simulations in one our use-cases). The output data can potentially include high-resolution sensor output, annotations, metadata, and simulation attributes necessary for later analysis and possibly re-simulation. All of this must be stored in an efficient database: that provides fast writing, efficient storage, and fast fetching of information.
The goal of this thesis is to develop an efficient approach to store said simulation data. The activities involved are as follows:
- Identify KPIs for comparing storage mechanisms for simulation data targeted for deep learning based systems
- Compare various technologies that can offer a solution based on the identified KPIs
- Integrate a database-framework with the multi-domain simulation framework VEROSIM
- (Optional) Adapt and integrate the database with VEROSIM within the RWTH Compute Cluster
- (Optional) Conduct research on commercial clouds e.g. Amazon Web Services, Google Cloud Platform and integration possibilities regarding the developed storage-framework
This thesis can be carried out in English or German.
Key Words: Databases, Parallel Simulation, AI-Data
Supervisor: Maqbool
Weitere Arbeiten







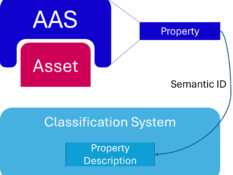
Klassifikationssystem für Merkmale Digitaler Zwillinge auf Basis der Industrie 4.0-Verwaltungsschale

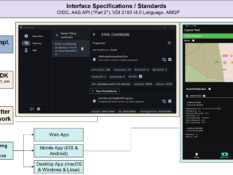




Implementation of an Accelerated Projected Gradient Descent Solver for Multibody Dynamics Simulation
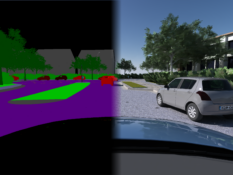



MA: Automatisierung der Verhandlung von digitalen Nutzungsrechten durch Self-sovereign Digital Twins